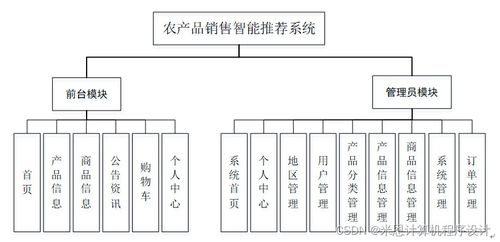
在基于Django的农产品销售智能推荐系统中,数据处理是整个系统的核心环节。它涉及从原始农产品数据中提取有效信息,并进行清洗、整合、分析和建模,以支持智能推荐功能。以下是数据处理的关键步骤和技术实现。
1. 数据采集与集成
系统首先需要采集农产品销售相关的多源数据,包括:
- 农产品基本信息(如名称、类别、价格、产地、季节性)。
- 用户行为数据(如浏览记录、购买历史、评分和评论)。
- 外部数据(如天气、市场趋势、节日因素)。
这些数据可通过数据库、API接口或Web爬虫获取,并通过Django的ORM(对象关系映射)工具进行集成,存储在关系型数据库(如MySQL或PostgreSQL)中。
2. 数据清洗与预处理
数据清洗是确保数据质量的关键步骤。常见操作包括:
- 处理缺失值:使用均值、中位数或基于规则的填充方法。
- 去除重复数据:通过唯一标识符(如产品ID)进行去重。
- 异常值检测:使用统计方法(如Z-score或IQR)识别和修正异常销售记录。
- 数据标准化:对价格、销量等数值型数据进行归一化,以消除量纲影响。
- 文本处理:对用户评论进行分词、去停用词和情感分析,提取用户偏好。
3. 数据存储与管理
Django框架支持多种数据库后端,数据处理过程中需合理设计数据模型。例如,定义Product、User、Transaction等模型,并建立关系(如一对多或多对多)。为提高查询效率,可引入缓存机制(如Redis)存储热点数据,或使用NoSQL数据库(如MongoDB)处理半结构化数据。
4. 特征工程与数据转换
为了构建推荐模型,需要进行特征工程:
- 数值特征:如农产品价格、折扣率、季节性指数。
- 类别特征:如产品类别、用户地域,通过独热编码或嵌入向量进行转换。
- 时间特征:如购买时间戳,提取年、月、日或季节信息。
- 协同过滤特征:基于用户-产品交互矩阵,计算相似度。
特征工程后,数据被转换为适合机器学习模型的格式,如稀疏矩阵或张量。
5. 推荐算法与数据处理集成
智能推荐系统通常采用混合推荐方法:
- 协同过滤:基于用户历史行为,使用矩阵分解(如SVD)或深度学习模型生成推荐。
- 内容过滤:利用农产品属性(如类别、产地)计算相似度。
- 关联规则:分析购买模式,发现频繁项集(如Apriori算法)。
数据处理模块通过Django的视图和任务队列(如Celery)定期更新模型,确保推荐结果实时性。
6. 数据安全与隐私保护
在数据处理中,必须考虑安全和隐私:
- 数据脱敏:对用户敏感信息(如联系方式)进行加密或匿名化。
- 访问控制:通过Django的权限系统限制数据操作。
- 合规性:遵循相关法规(如GDPR),确保数据使用合法。
7. 数据监控与优化
系统运行时,需监控数据处理性能:
- 日志记录:使用Django日志模块跟踪数据流程和错误。
- 性能分析:通过数据库查询优化和索引提升效率。
- A/B测试:评估不同数据处理策略对推荐效果的影响。
在Django农产品销售智能推荐系统中,数据处理是连接用户与产品的桥梁。通过高效的数据采集、清洗、存储和建模,系统能够提供个性化推荐,提升用户体验和销售效率。可引入实时流处理(如Apache Kafka)和更先进的AI模型,进一步优化数据处理能力。